



Despite the rapid adoption of Artificial Intelligence (AI) automation across industries, there is still a considerable amount of skepticism surrounding intelligent automation technologies.
Many professionals are cynical about the accuracy and reliability of AI. As a consequence, senior decision-makers still feel more at home with human-centric processes – even though they could utilize these resources in other areas of the business.
In contrast to the concerns surrounding AI, it is already more accurate than experts in many fields.
Here we dispel these common myths about process optimization and look at how you can take control of AI-enabled workflow automation for increased business success.
Dispelling AI skepticism: The lost value of intelligent automation
Rather than merely executing rule-based repetitive tasks, intelligent automation with AI empowers businesses to evolve by optimizing the way complex functions are conducted that require cognitive abilities. In doing so, organizations across industries gain the potential to free up their employees to work on more fulfilling initiatives, thereby exceeding their current potential.
An AI-powered process optimization is a powerful tool with a wealth of business-boosting benefits. However, concerns surrounding its reliability are a major roadblock to mainstream adoption.
Many businesses do not trust AI automation technology to carry out human tasks for fear of uncontrollable errors when, in reality, automation technology can enhance performance and reliability by reducing possibilities for human error.
Humans, by their very nature, will always make mistakes.
Nothing in this world is absolute, which means that AI will never be 100% accurate. But: In contrast, machines work with diligence based on pre-specified commands, without nuance or fluctuation. Since the mistakes machines make are predictable while human error is far more random, you can systematically regulate the amount and types of errors you are willing to accept.
Also, keep in mind that to improve performance, an AI algorithm that replaces a human expert doesn’t need to make zero errors. It merely needs to make fewer errors than human experts.
In a 2018 study, the startup LawGeex analyzed the performance of lawyers in comparison to Artificial Intelligence when assessing the quality of non-disclosure agreements. In the experiment, 20 experienced lawyers were compared to LawGeex’s proprietary AI platform. Participants evaluated the risks contained in five different NDA agreements by searching for 30 specific legal points.

According to the results of the study, AI showed an average accuracy of 94%, whereas people achieved 85%. At the same time, the AI’s maximum accuracy was 100%. The lawyers ': 94%. On average, people required 92 minutes to accomplish the task, while the AI analyzed all the documents in 26 seconds.
Intelligent automation, if harnessed the right way, can help people reach their full professional potential while driving down the probability of error, and increasing productivity across the board. However, sometimes even AI-enabled decision support can deliver great benefits.
Measures to ensure AI accuracy
Even the world’s most prolific specialists can make fatal mistakes. Machines can too. However, if AI automation makes fewer mistakes than its human counterparts, it is an improvement.
As mentioned, autonomous technologies already have the potential to be more accurate than human experts. On top, you have better control over the mistakes a machine makes since you can directly influence their type and frequency and align them with your goals.
When considering AI process automation for your business, rather than aiming for absolute perfection (albeit a mythical beast in the real-world – digital or otherwise), you should think about which trade-offs you are willing to make.
One trade-off is about accuracy vs. automation: How often do you want to manually interfere to avoid mistakes? The second is false positives vs. false negatives: Would you rather make a wrong detection or miss a detection?
To put these trade-offs into action, you need to create a confidence level (CL) contingency plan.
Understanding confidence levels
The gateway to learning how to control process automation with AI is understanding the concept of confidence levels.
When making a prediction, a Machine Learning model will often tell you how sure it is that its choice is true. A measurement for this is the confidence level which ranges between 0% and (only theoretically) 100%. In other words, the confidence level estimates the likelihood that the prediction is true.
By quantifying thresholds for confidence levels, you can regulate how many mistakes your model will make. However, there are two things to consider:
1. The percentage you choose needs to be related to your model and data
A confidence threshold of 95% does not mean that we "allow" the model to make five mistakes for every 100 predictions. In a dog classifier, for example, regular dog photos might very well receive a 99.99% confidence level most of the time.
Therefore, rather than blindly setting a threshold, you should look at your data points with complementary confidence levels and decide which elements should be accepted or rejected for different thresholds.

2. The effect of confidence levels changes dynamically if the model learns
If you intervene to manually label difficult cases, your model will improve along the way. This means it will get a better understanding of what you are looking for and make fewer mistakes if the confidence thresholds stay the same. Therefore, it is normally advisable to adjust confidence thresholds as accuracy improves.
Creating a confidence level contingency plan
The simplest way to set up ML-automation is to set one threshold at and above which a prediction is accepted and below which it is rejected.
However, to ensure efficient, yet controlled automation, we suggest that you implement a plan with two thresholds. This plan will require a Human-in-the-Loop (HITL), a person (or more) that will manually label difficult cases, as well as automated acceptance or rejection models. It will look something like this:

Let's look at the three colored areas in more detail:
Above a higher threshold
The Machine Learning model or AI application will automatically accept the prediction. For high confidence levels, it makes sense to automate the process since the machine will likely make very few mistakes.
The type of mistake a machine can make here is to accept a choice that should be rejected which is called a false positive, as will be explained later. Of course, the higher you set this upper threshold, the fewer mistakes the AI will make. However, this comes at a cost:
Between the thresholds
The case will be sent to a Human-in-the-Loop who will check and decide manually. Increasing the gap between the thresholds will decrease mistakes made by the machine. However, it also increases the amount of costly manual work which slows down automation.
Still, finding the right amount of manual intervention is key to enabling reinforcement learning so predictions get better along the way. Also, it is an important control mechanism to catch systematic mistakes early and make strategic adjustments. This second benefit is especially important to keep in mind when you are thinking about outsourcing the HITL to third-party click-workers.
Below a lower threshold
The model or application will automatically reject the hypothesis. Keep in mind, that there is nothing like a negative confidence level that can tell you that the machine thinks the hypothesis is definitely wrong. Low confidence levels for predictions should not be understood as "I think this might be a dog" but rather as "No, no, no this is furry thing is clearly not a dog – give me a different label and I'll tell you what it is."
If you increase the percentage, more elements will be directly rejected. Since at some point, also true but difficult cases will fall under this automatic rejection, you will eventually produce false negatives.
Let's take a closer look at this:
Understanding errors: false positives vs. false negatives
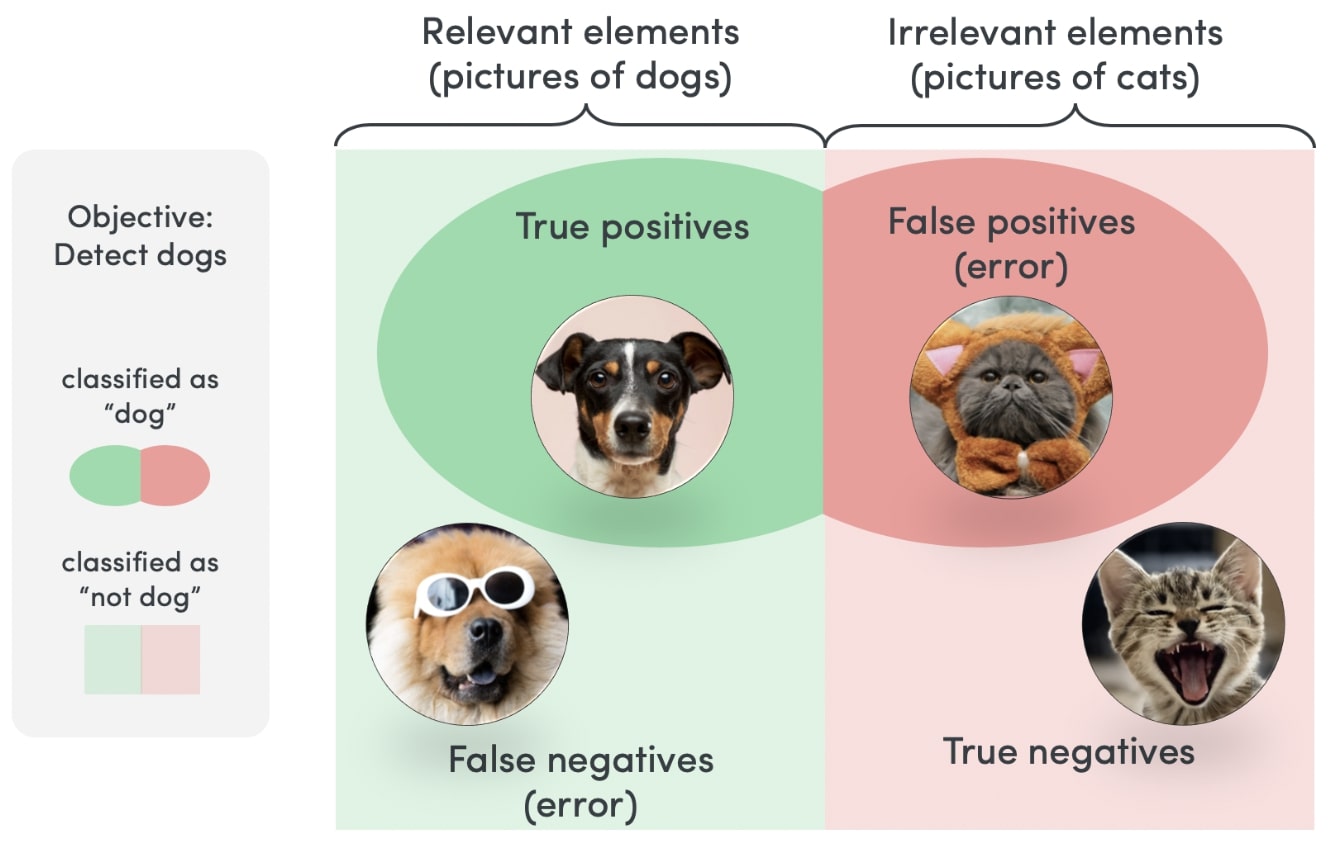
When searching for specific elements, ML models, just like statistical models, can make two types of mistakes.
One mistake is that the machine detects an irrelevant element as the element of interest. This is called a false positive or type I error.
The second one is missing an element that should be detected. We call this a false negative or type II error.
In the illustration below, an image classifier had the objective to detect pictures of dogs out of a dataset containing photos of cats and dogs. The true positives are the dogs the model successfully detected. The true negatives are pictures of cats that were classified as "not dog".
In our case, the false positives were cats that were able to fool the algorithm by trying really hard to be detected as dogs while the false negatives were dogs that succeeded to camouflage their dogly appearance. Read more about this in our article on precision vs. recall.
In an ML-enabled automation context, you can influence the types and amount of errors by moving the lower (false negatives) and upper threshold (false positives). While doing so, you should always keep in mind three factors: the cost of manual interaction, the cost of a wrong detection, and the cost of a missed detection.
False positives
A model tweaked to favor false positives will present fewer missed detections but return more poor detections.
This outcome setting is favorable in industries where missed detections are costly and/or manual checks can be done quickly.
Take the medical sector, for instance. If you’re automating imaging for cancer detection, false positive results are likely to take just 10 minutes of a doctor’s time to check the image manually and make the right decision. In contrast, a false negative could have lethal consequences since cancer remains undetected.
Also, if what is to detect is rare, the trade-off of checking a few elements manually is likely worth the while if it increases the likelihood of detecting the data point you were looking for. Use cases for this range from discovering distant objects in outer space to finding illicit user-generated content on social media.
False negatives
In contrast, a model that tends to allow more false negatives than false positives may miss more detections. Thus, it is based on the notion of better quality decisions and more data misses.
Allowing more false negatives makes sense for applications in which a missed detection is harmless and should not stand in the way of automation.
For example, if you are working with large image datasets that you want to pre-sort before starting your manual analysis it might not be a problem if a picture doesn't fit here or there. However, taking the time to manually label all of these cases might defeat the original purpose of the automated sorting.
Also if you are looking for a few high-quality elements and don't care about the rest of the data, you should opt for a high likelihood of false negatives and a low likelihood of false positives. Doing so will enable you to automate a large chunk of the process and provide you with fewer, qualitative detections.
Essentially, instead of searching for perfection, the best course of action is to decide which side of the coin your organization falls on – and act accordingly.
Intelligent automation and improved reliability? You can have both
AI can already beat human experts in many disciplines in terms of speed and accuracy. It is not 100% accurate all of the time, but mistakes can be systematically controlled and improved based on confidence level contingency plans involving confidence thresholds and a Human in the Loop.
Which trade-offs you make is ultimately your choice and should be aligned with your business. While Artificial Intelligence isn't the solution to all of your problems, making use of it enhances the efficiency of your business while offering long-term operational benefits.
By understanding the fundamental dynamics of ML models and creating a confidence level contingency plan, you will enhance your business through AI-enabled process automation without risking reliability.